





Abstract
Background: Long non-coding RNAs (lncRNAs) are transcripts with a length more than 200 nucleotides, functioning in the regulation of gene expression. More evidence has shown that the biological functions of lncRNAs are intimately related to their subcellular localizations. Therefore, it is very important to confirm the lncRNA subcellular localization.
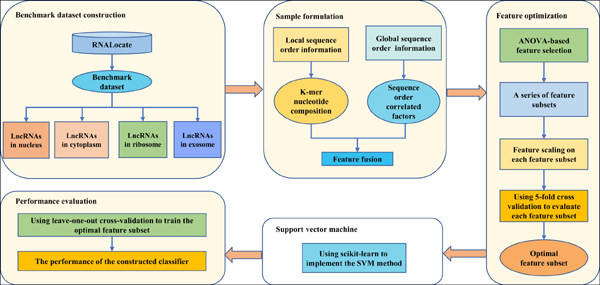
Methods: In this paper, we proposed a novel method to predict the subcellular localization of lncRNAs. To more comprehensively utilize lncRNA sequence information, we exploited both kmer nucleotide composition and sequence order correlated factors of lncRNA to formulate lncRNA sequences. Meanwhile, a feature selection technique which was based on the Analysis Of Variance (ANOVA) was applied to obtain the optimal feature subset. Finally, we used the support vector machine (SVM) to perform the prediction.
Results: The AUC value of the proposed method can reach 0.9695, which indicated the proposed predictor is an efficient and reliable tool for determining lncRNA subcellular localization. Furthermore, the predictor can reach the maximum overall accuracy of 90.37% in leave-one-out cross validation, which clearly outperforms the existing state-of- the-art method.
Conclusion: It is demonstrated that the proposed predictor is feasible and powerful for the prediction of lncRNA subcellular. To facilitate subsequent genetic sequence research, we shared the source code at https://github.com/NicoleYXF/lncRNA.
Keywords: Long non-coding RNA, subcellular localization, sequence order correlated factors, feature selection, analysis of variance, support vector machine.
Graphical Abstract
[http://dx.doi.org/10.18632/oncotarget.11141] [PMID: 27517318]
[http://dx.doi.org/10.4161/rna.24604] [PMID: 23696037]
[http://dx.doi.org/10.1016/j.canlet.2015.02.035] [PMID: 25721084]
[http://dx.doi.org/10.1186/1480-9222-16-11] [PMID: 25276098]
[http://dx.doi.org/10.1111/febs.12737] [PMID: 24495014]
[http://dx.doi.org/10.1210/er.2014-1034] [PMID: 25426780]
[http://dx.doi.org/10.1016/j.gpb.2015.09.006] [PMID: 26883671]
[http://dx.doi.org/10.1007/s00018-016-2174-5] [PMID: 27007508]
[http://dx.doi.org/10.1186/s13578-018-0208-4] [PMID: 29441193]
[PMID: 26208723]
[http://dx.doi.org/ 10.1007/s40572-016-0092-1]
[http://dx.doi.org/10.1186/s13059-015-0586-4] [PMID: 25630241]
[http://dx.doi.org/10.1016/j.tibs.2016.07.003] [PMID: 27499234]
[http://dx.doi.org/10.1093/database/bay085] [PMID: 30219837]
[http://dx.doi.org/10.1186/gb-2014-15-1-r6] [PMID: 24393600]
[PMID: 27543076]
[http://dx.doi.org/10.1261/rna.060814.117] [PMID: 28386015]
[http://dx.doi.org/10.1093/bioinformatics/bty085] [PMID: 29462250]
[http://dx.doi.org/10.1093/bioinformatics/bty508] [PMID: 29931187]
[http://dx.doi.org/10.1002/prot.1035] [PMID: 11288174]
[http://dx.doi.org/10.1093/bioinformatics/bth466] [PMID: 15308540]
[http://dx.doi.org/10.1016/j.jtbi.2013.06.034] [PMID: 23850480]
[http://dx.doi.org/10.1155/2013/263829] [PMID: 24027753]
[http://dx.doi.org/10.1016/j.jtbi.2014.04.006] [PMID: 24732262]
[http://dx.doi.org/10.1371/journal.pone.0105018] [PMID: 25121969]
[http://dx.doi.org/10.1016/j.ab.2015.12.009] [PMID: 26723495]
[http://dx.doi.org/10.1039/C5MB00883B] [PMID: 26883492]
[http://dx.doi.org/10.1155/2016/5413903] [PMID: 27597968]
[http://dx.doi.org/10.1016/j.jtbi.2015.11.009] [PMID: 26702543]
[http://dx.doi.org/10.1016/j.jtbi.2010.12.024] [PMID: 21168420]
[http://dx.doi.org/10.1016/j.ab.2014.04.001] [PMID: 24732113]
[http://dx.doi.org/10.1039/C5MB00155B] [PMID: 26099739]
[http://dx.doi.org/10.1155/2014/623149] [PMID: 24967386]
[http://dx.doi.org/10.1016/j.ab.2015.08.021] [PMID: 26314792]
[http://dx.doi.org/10.1038/srep40242] [PMID: 28079126]
[http://dx.doi.org/10.1016/j.ab.2018.09.002] [PMID: 30201554]
[http://dx.doi.org/10.1093/bioinformatics/btv604] [PMID: 26476782]
[http://dx.doi.org/10.1093/bioinformatics/btw186] [PMID: 27153623]
[http://dx.doi.org/10.1016/j.chemolab.2014.12.011]
[http://dx.doi.org/10.18632/oncotarget.11975] [PMID: 27626500]
[http://dx.doi.org/10.1016/j.omtn.2017.04.008] [PMID: 28624202]
[http://dx.doi.org/10.1089/cmb.2018.0004] [PMID: 30113871]
[http://dx.doi.org/10.1007/s12539-016-0193-4] [PMID: 27739055]
[http://dx.doi.org/10.1093/bioinformatics/btu820] [PMID: 25504848]
[http://dx.doi.org/10.1093/nar/gkv458] [PMID: 25958395]
[http://dx.doi.org/10.1007/s00438-015-1078-7] [PMID: 26085220]
[http://dx.doi.org/10.18632/oncotarget.14524] [PMID: 28076851]
[http://dx.doi.org/10.4236/ns.2017.94007]
[http://dx.doi.org/10.2174/1573406411666141229162834 PMID: 25548930]
[http://dx.doi.org/10.3389/fmicb.2018.02174] [PMID: 30258427]
[http://dx.doi.org/10.1186/s12859-017-1881-8] [PMID: 29100493]
[http://dx.doi.org/10.1093/bioinformatics/btx517] [PMID: 28961926]
[http://dx.doi.org/10.1109/TCYB.2016.2524994] [PMID: 28113829]
[http://dx.doi.org/10.1186/s12918-017-0389-1] [PMID: 28361702]
[http://dx.doi.org/10.1016/j.ab.2015.12.017] [PMID: 26748145]
[http://dx.doi.org/10.1039/C4MB00645C] [PMID: 25437899]
[http://dx.doi.org/10.1016/j.chemolab.2018.07.006]
[http://dx.doi.org/10.3109/10409239509083488] [PMID: 7587280]
[http://dx.doi.org/10.1093/bioinformatics/btx476] [PMID: 29036535]
[http://dx.doi.org/10.4236/ns.2017.99032]
[http://dx.doi.org/10.1016/j.ab.2013.05.024] [PMID: 23756733]
[http://dx.doi.org/10.1039/C5MB00050E] [PMID: 25715848]
[http://dx.doi.org/10.1039/c3mb25555g] [PMID: 23536215]
[http://dx.doi.org/10.1093/bioinformatics/btx387] [PMID: 28172617]
[http://dx.doi.org/10.1016/S0031-3203(96)00142-2]
[http://dx.doi.org/10.2174/1570178614666170213102455]
[http://dx.doi.org/10.1093/nar/gkh954] [PMID: 15562006]
[http://dx.doi.org/10.1186/gb-2007-8-12-r263] [PMID: 18072969]
[http://dx.doi.org/10.1073/pnas.83.24.9373] [PMID: 2432595]










Related Books

Industrial Applications of Soil Microbes

Genome Editing in Bacteria (Part 2)

Aromatherapy: The Science of Essential Oils

In Vitro Propagation and Secondary Metabolite Production from Medicinal Plants: Current Trends (Part 2)

Micropropagation of Medicinal Plants

Software and Programming Tools in Pharmaceutical Research

Biotechnology and Drug Development for Targeting Human Diseases

In Vitro Propagation and Secondary Metabolite Production from Medicinal Plants: Current Trends (Part 1)

Molecular and Physiological Insights into Plant Stress Tolerance and Applications in Agriculture- Part 2

Micropropagation of Medicinal Plants
 30
30