





Abstract
Background: Identification of Enzyme Commission (EC) number of enzymes is quite important for understanding the metabolic processes that produce enough energy to sustain life. Previous studies mainly focused on predicting six main functional classes or sub-functional classes, i.e., the first two digits of the EC number.
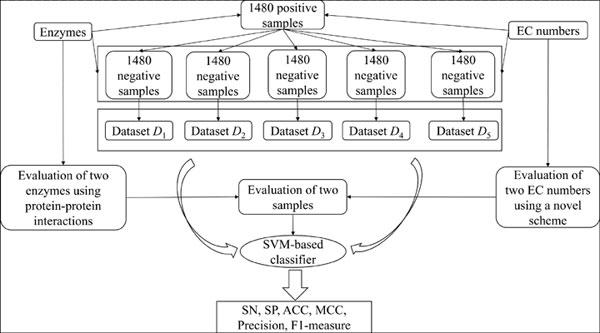
Objective: In this study, a binary classifier was proposed to identify the full EC number (four digits) of enzymes.
Methods: Enzymes and their known EC numbers were paired as positive samples and negative samples were randomly produced that were as many as positive samples. The associations between any two samples were evaluated by integrating the linkages between enzymes and EC numbers. The classic machining learning algorithm, Support Vector Machine (SVM), was adopted as the prediction engine.
Results: The five-fold cross-validation test on five datasets indicated that the overall accuracy, Matthews correlation coefficient and F1-measure were about 0.786, 0.576 and 0.771, respectively, suggesting the utility of the proposed classifier. In addition, the effectiveness of the classifier was elaborated by comparing it with other classifiers that were based on other classic machine learning algorithms.
Conclusion: The proposed classifier was quite effective for prediction of EC number of enzymes and was specially designed for dealing with the problem addressed in this study by testing it on five datasets containing randomly produced samples.
Keywords: Enzyme, EC number, support vector machine, protein-protein interaction, Weka, binary classification, five-fold cross-validation.
Graphical Abstract
Call for Papers in Thematic Issues
Mass spectrometry data acquisition and analysis for proteomics
The Thematic Issue on "Mass spectrometry data acquisition and analysis for proteomics" aims to explore the latest advancements and challenges in the field of proteomics through the lens of mass spectrometry. Proteomics, the large-scale study of proteins and their functions, plays a crucial role in understanding various biological processes and ...read more
Peptides: State-of-Art and Commercialisation Hurdles
The Editors of the Current Proteomics (CP) journal are highly privileged to welcome scientists to submit their scientific research and review articles to be considered for publication in the upcoming thematic issue. The topics should cover various aspects of peptides in regard to their synthetic methodologies, formulation approaches, pharmacological challenges, ...read more
Related Journals

Current Bioactive Compounds

Combinatorial Chemistry & High Throughput Screening

Current Diabetes Reviews

Current Enzyme Inhibition

Current Molecular Medicine

Current Medicinal Chemistry

Current Pharmaceutical Biotechnology

Current Topics in Medicinal Chemistry

Current Protein & Peptide Science

Medicinal Chemistry
Related Books

Research Methodology and Project Management in Biotechnology

Recent Progress in Pharmaceutical Nanobiotechnology: A Medical Perspective

Recent Trends In Livestock Innovative Technologies

Algal Biotechnology for Fuel Applications

Terpenoids: Recent Advances in Extraction, Biochemistry and Biotechnology

Recent Advances in Biotechnology
 70
70 4
4