





Abstract
Objective: Biomedical data can be de-identified via micro-aggregation achieving k - anonymity privacy. However, the existing micro-aggregation algorithms result in low similarity within the equivalence classes, and thus, produce low-utility anonymous data when dealing with a sparse biomedical dataset. To balance data utility and anonymity, we develop a novel microaggregation framework.
Methods: Combining a density-based clustering method and classical micro-aggregation algorithm, we propose a density-based second division micro-aggregation framework called DBTP . The framework allows the anonymous sets to achieve the optimal k- partition with an increased homogeneity of the tuples in the equivalence class. Based on the proposed framework, we propose a k − anonymity algorithm DBTP − MDAV and an l − diversity algorithm DBTP − l − MDAV to respond to different attacks.
Conclusions: Experiments on real-life biomedical datasets confirm that the anonymous algorithms under the framework developed in this paper are superior to the existing algorithms for achieving high utility.
Keywords: Privacy protection, micro-aggregation, k − anonymity, l − diversity, clustering, biomedical data.
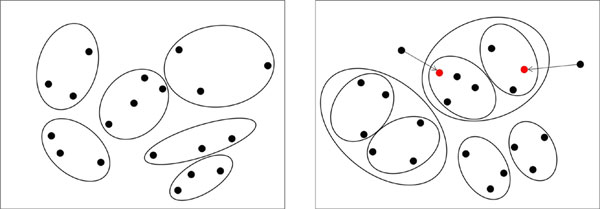
Graphical Abstract










Related Books

In Vitro Propagation and Secondary Metabolite Production from Medicinal Plants: Current Trends (Part 2)

Micropropagation of Medicinal Plants

Software and Programming Tools in Pharmaceutical Research

Biotechnology and Drug Development for Targeting Human Diseases

In Vitro Propagation and Secondary Metabolite Production from Medicinal Plants: Current Trends (Part 1)

Molecular and Physiological Insights into Plant Stress Tolerance and Applications in Agriculture- Part 2

Micropropagation of Medicinal Plants

Genome Editing in Bacteria (Part 1)

Data Science for Agricultural Innovation and Productivity

Animal Models In Experimental Medicine
 43
43 3
3 1
1 1
1